Adventures in Avoiding DAIS Buffers
After watching Horizon Forbidden West’s presentation on their usage of visibility buffers (an approach that avoids such an attachment in favor of a reconstructing those derivatives from a limited buffer of post-transform triangles – called Deferred Attribute Interpolation Shading, or DAIS), it became apparent my approach was suboptimal.
August 16, 2024,
Prelude
One of the most rewarding aspects of working on an engine made to sustain a large amount of content on a small memory and performance budget has been the opportunity to sample and evaluate optimization techniques as they enter and re-enter the graphics conversation. One such technique is Visibility Buffer rendering [1], re-popularized as it underpins opaque material rendering in Unreal Engine 5’s Nanite [2]. Of course, different approaches to doing ‘deferred materials’ were both discussed and practiced long before the advent of Nanite’s material tiles [3][4] with Dawn engine’s clever usage of depth testing to isolate material shading being of note [5].
Epic’s impressive Valley of the Ancients showcase [6] prompted me to bring some of this into my own work. My initial effort [7] contained having an extra RGBA32F attachment containing dFdx(uv) and dFdy(uv) as these are necessary parameters to textureQueryLod() for proper texture sampling that accounts for anisotropic filtering (readily available during hardware rasterization). However, after watching Horizon Forbidden West’s presentation on their usage of visibility buffers [8] (an approach similar to [9] that avoids such an attachment in favor of a reconstructing those derivatives from a limited buffer of post-transform triangles – called Deferred Attribute Interpolation Shading, or DAIS) it became apparent my approach was suboptimal.
Re-inventing a (similar) wheel
After some quick thinking, I decided to drop the attachment entirely and reduce all my attachments to contain two 32-bit numbers (instance and triangle IDs – though most production engines will reduce both of those to 16-bits or do a 24 and 8-bit combo) by re-constructing barycentric coordinates followed by UV gradients via utilizing ray differentials [10]. The approach [11] consisted of:
- Casting 3 rays from the viewer towards the triangle in world space as stored in the vertex buffer:
- one directed from the pixel center, another offset by 1 pixel to the right and another offset by 1 pixel to the bottom
- Constructing barycentric coordinates from each hit using the technique prescribed in [12]
- Reconstructing UVs for all 3 hits
- Subtracting the UVs to get fine-grained dFdx(uv) and dFdy(uv)s
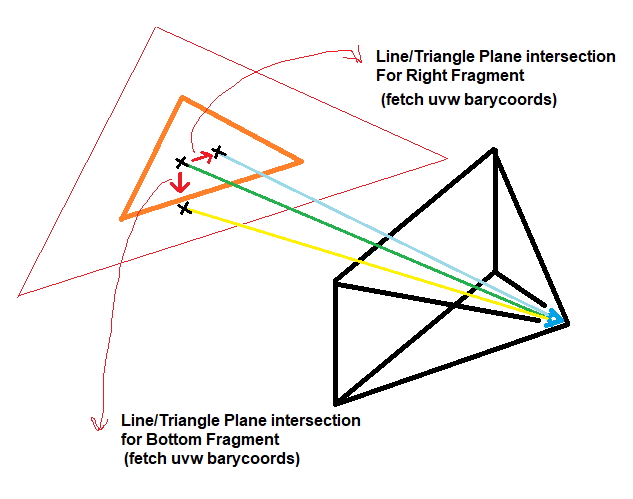
vec3 barycentricCoords(vec3 p, vec3 a, vec3 b, vec3 c) { vec3 v0 = b - a, v1 = c - a, v2 = p - a; float d00 = dot(v0, v0); float d01 = dot(v0, v1); float d11 = dot(v1, v1); float d20 = dot(v2, v0); float d21 = dot(v2, v1); float invDenom = 1.0 / (d00 * d11 - d01 * d01); float v = (d11 * d20 - d01 * d21) * invDenom; float w = (d00 * d21 - d01 * d20) * invDenom; float u = 1.0 - v - w; return vec3 (u,v,w); } void main() { ... vec2 pixelFootPrint = vec2(1.0) / outputSize; vec3 viewEye = vec3 (frameMVP.lookEyeX.a, frameMVP.upEyeY.a, frameMVP.sideEyeZ.a); vec3 curFNorm = normalize (cross (curTri.e1Col1.xyz - curTri.e2Col2.xyz, curTri.e3Col3.xyz - curTri.e2Col2.xyz)); float topIsectTime = dot (curFNorm, curTri.e1Col1.xyz) - dot (viewEye, curFNorm); vec2 curRayUV = inUV * 2.0 - vec2 (1.0); vec2 rayDiff1UV = (inUV + vec2 (pixelFootPrint.x, 0.0)) * 2.0 - vec2(1.0); vec2 rayDiff2UV = (inUV + vec2 (0.0, pixelFootPrint.y)) * 2.0 - vec2(1.0); vec3 curRay = frameMVP.lookEyeX.xyz - curRayUV.y * frameMVP.upEyeY.xyz * frameMVP.whrTanHalfFovYReserved.y - curRayUV.x * frameMVP.sideEyeZ.xyz * frameMVP.whrTanHalfFovYReserved.y * frameMVP.whrTanHalfFovYReserved.x; vec3 rayDiff1 = frameMVP.lookEyeX.xyz - rayDiff1UV.y * frameMVP.upEyeY.xyz * frameMVP.whrTanHalfFovYReserved.y - rayDiff1UV.x * frameMVP.sideEyeZ.xyz * frameMVP.whrTanHalfFovYReserved.y * frameMVP.whrTanHalfFovYReserved.x; vec3 rayDiff2 = frameMVP.lookEyeX.xyz - rayDiff2UV.y * frameMVP.upEyeY.xyz * frameMVP.whrTanHalfFovYReserved.y - rayDiff2UV.x * frameMVP.sideEyeZ.xyz * frameMVP.whrTanHalfFovYReserved.y * frameMVP.whrTanHalfFovYReserved.x; vec3 curPos = viewEye + (topIsectTime/dot (curRay, curFNorm)) * curRay; vec3 isect1 = viewEye + (topIsectTime/dot (rayDiff1, curFNorm)) * rayDiff1; vec3 isect2 = viewEye + (topIsectTime/dot (rayDiff2, curFNorm)) * rayDiff2; vec3 curIsectBary = barycentricCoords (curPos, curTri.e1Col1.xyz, curTri.e2Col2.xyz, curTri.e3Col3.xyz); vec3 isect1Bary = barycentricCoords (isect1, curTri.e1Col1.xyz, curTri.e2Col2.xyz, curTri.e3Col3.xyz); vec3 isect2Bary = barycentricCoords (isect2, curTri.e1Col1.xyz, curTri.e2Col2.xyz, curTri.e3Col3.xyz); vec2 curUV = curTri.uv1Norm1.xy * curIsectBary.x + curTri.uv2Norm2.xy * curIsectBary.y + curTri.uv3Norm3.xy * curIsectBary.z; vec2 rightUV = curTri.uv1Norm1.xy * isect1Bary.x + curTri.uv2Norm2.xy * isect1Bary.y + curTri.uv3Norm3.xy * isect1Bary.z; vec2 bottomUV = curTri.uv1Norm1.xy * isect2Bary.x + curTri.uv2Norm2.xy * isect2Bary.y + curTri.uv3Norm3.xy * isect2Bary.z; vec4 dUVdxdy = vec4 (rightUV - curUV, bottomUV - curUV); ... }
If rules around MSAA were any indication, some rays hitting outside triangle boundaries would be perfectly fine. As witnessed in [11], the results were almost a match with those same values produced from the hardware rasterizer.
Shortly after unveiling, it would be brought to my attention that my approach had a distinct similarity to the supplemental code in [1] that I had missed! However, with key distinctions: said code inverse projected trace origins and directions to intersect with triangles in object space. I had no need for this for one simple reason: at the time, all my animated geometry – including those of rigid bodies – were all transformed inside compute shaders and backed by unique vertex memory. To save memory, I would even go as far as multiplying an incoming transform with a rigid body’s previous worldspace transform to save on not keeping two copies. This was ok at the time as most rigid bodies intended for the game I’m working on were unique pieces of geometry generated by CSG operations [13]. Naturally for a world where foliage is plastered around a landscape via affine transforms my approach would be too wasteful as you want the same foliage geometry just rendered many times over. Yet another point brought to my attention around this time.
A solution-shaped butterfly? Or a butterfly-shaped solution?
In an interesting turn of events, I would work with an artist on my game project whose affinity for instancing was quite pronounced in his workflow. As a result I would once again implement instancing in my engine. The engine indeed had instancing in a previous iteration which had been retired due to nature of the content described above as well as constraints imposed by hardware raytracing APIs (i.e. DXR or related Vulkan extensions forcing compute skinning and unique geometry for skinned meshes). One of my hard goals was hardware raytracing support alongside a form of software raytracing.
So did this mean that I would finally need a DAIS buffer [8][9]? Did I have to now I switch to inverse transforms per fragment like that of [1]? Or perhaps follow Unreal Engine’s approach of auto-differentiating the derivatives in postprocess per fragment per material [14]?1
The answer came once again in the form of another small light bulb moment: re-use LDS memory in compute as a drop-in DAIS buffer [15]. Simply transform the first triangle in the workgroup and cache its edges and vertex normals in shared memory along with its instance and triangle IDs. If further work items in the workgroup share the same instance and triangle IDs, simply re-use the same edges and normals cached for the entire workgroup. Otherwise, re-use is not possible and transformations for the work item (fragment) must be performed independently. As witnessed, when on-screen triangle density is low quite a lot of re-use can happen! Worst case scenario is a re-transform per every fragment on screen which is not unheard of. Worthy to note that my engine re-derives the entire tangent space during the material pass using linear dependence: tangents and bi-tangents do not take up space in the compact 24-byte vertex format that the engine uses.
shared uvec2 cachedInstTriID; shared vec3 cachedE1, cachedE2, cachedE3, cachedN1, cachedN2, cachedN3; ... vec3 curTriE1, curTriE2, curTriE3; vec3 curTriN1, curTriN2, curTriN3; TriangleFromVertBufWide curTri; if (!returnFunc) { ReadTri (curTri, instanceInfo.props[InstID].triOffset, TriID); if (gl_LocalInvocationID.xy == uvec2 (0)) { cachedInstTriID = triInfoFetch; cachedE1 = (transforms.mats[instanceInfo.props[InstID].transformOffset] * vec4 (curTri.e1Col1.xyz, 1.0)).xyz; cachedE2 = (transforms.mats[instanceInfo.props[InstID].transformOffset] * vec4 (curTri.e2Col2.xyz, 1.0)).xyz; cachedE3 = (transforms.mats[instanceInfo.props[InstID].transformOffset] * vec4 (curTri.e3Col3.xyz, 1.0)).xyz; mat4 transformDT = DirectionTransform(transforms.mats[instanceInfo.props[InstID].transformOffset ]); cachedN1 = (transformDT * vec4 (fromZSignXY (curTri.Norm1), 1.0)).xyz; cachedN2 = (transformDT * vec4 (fromZSignXY (curTri.Norm2), 1.0)).xyz; cachedN3 = (transformDT * vec4 (fromZSignXY (curTri.Norm3), 1.0)).xyz; // This section might skin if the instance is 'skinned geometry' for example... } } memoryBarrier(); barrier(); if (returnFunc) return ; if (cachedInstTriID == triInfoFetch) { curTriE1 = cachedE1; curTriE2 = cachedE2; curTriE3 = cachedE3; curTriN1 = cachedN1; curTriN2 = cachedN2; curTriN3 = cachedN3; cacheReuse = true; } else { curTriE1 = (transforms.mats[instanceInfo.props[InstID].transformOffset] * vec4 (curTri.e1Col1.xyz, 1.0)).xyz; curTriE2 = (transforms.mats[instanceInfo.props[InstID].transformOffset] * vec4 (curTri.e2Col2.xyz, 1.0)).xyz; curTriE3 = (transforms.mats[instanceInfo.props[InstID].transformOffset] * vec4 (curTri.e3Col3.xyz, 1.0)).xyz; mat4 transformDT = DirectionTransform(transforms.mats[instanceInfo.props[InstID].transformOffset ]); curTriN1 = (transformDT * vec4 (fromZSignXY (curTri.Norm1), 1.0)).xyz; curTriN2 = (transformDT * vec4 (fromZSignXY (curTri.Norm2), 1.0)).xyz; curTriN3 = (transformDT * vec4 (fromZSignXY (curTri.Norm3), 1.0)).xyz; // This section might skin if the instance is 'skinned geometry' for example... } // curTriE1/E2/E3/N1/N2/N3 are used for everything else past this point... ...
Conclusion
My biggest takeaway in this journey was the indispensable feedback of likeminded peers within a journey of technical discovery. Working in solitude most certainly has its joys: you are unconstrained by immediate business needs and you can explore research topics that excite you. However, competent peers and mentors are indispensable allies that can sharpen your vision, alleviate your blind spots, and be shoulders upon which truly great work can happen and I certainly desire to increase participation in such engagements going forward.
Footnotes
For the curious who have UE5 code access: set r.Shaders.AllowCompilingThroughWorkers to 0 in ConsoleVariables.ini, fire up the Editor attached, make a meaningless change to MaterialTemplate.ush, execute `recompileshaders changed` in console, modify CompileD3DShader(…) in D3DShaderCompiler.cpp to save shaders containing CalcPixelMaterialInputsAnalyticDerivatives(…) to text files, observe the TransformNaniteTriangle(…) call within FetchNaniteMaterialPixelParameters(…) in saved Nanite-related shaders.
References
DOI:
DOI:
DOI:
DOI:
DOI:
DOI:
DOI:
DOI:
DOI:
DOI:
DOI:
DOI:
DOI:
DOI:
DOI:
Adventures in avoiding DAIS buffers by Baktash Abdollah-Shamshir-saz is licensed under CC BY-NC 4.0![]()
![]()
![]()
Share this story. Choose your platform.
Want more updates and information from ACM? Sign up for our Newsletter.
Related Articles

An Empirical Study of VR Head-Mounted Displays Based on VR Games Reviews
In recent years, the VR tech boom has signaled fruitful applications in various fields.
August 22, 2024,

Pokémon GO as an Advertising Platform
This article explores a notable gap in the literature on locative media: the impacts of LBA on small businesses in the location-based game Pokémon GO.
August 11, 2024,

Adventures in Avoiding DAIS Buffers
After watching Horizon Forbidden West’s presentation on their usage of visibility buffers, it became apparent my approach was suboptimal.
August 16, 2024,

